Get up to speed in just over minute with this audio summary…
A speedy listen, generated using Google Notebook LM.
Imagine your data pipeline is a busy motorway carrying thousands of vehicles from one place to another. Based in a motorway service station, you’ve been given the task to check all the red cars hurtling down the road while minimising the disruption to the rest of the traffic.
How would you do it?

Stop the Motorway (ETL)

Well, you could stop the entire motorway and turn all three lanes into a checking area. Every vehicle comes to a halt. You inspect them one by one, whether they’re red cars or not. Then, once everything has been checked, you restart all the traffic.
This is classic ETL behaviour. It works, it’s simple and only requires one process, so there are no integration requirements.
The fundamental problem with this approach is that all traffic has had to stop. The entire motorway is gridlocked while you’re checking. With the speed of the checking process depending entirely on how much power you have. This is particularly troublesome if your data is interconnected or time-dependent.
Park the Cars (Batch)
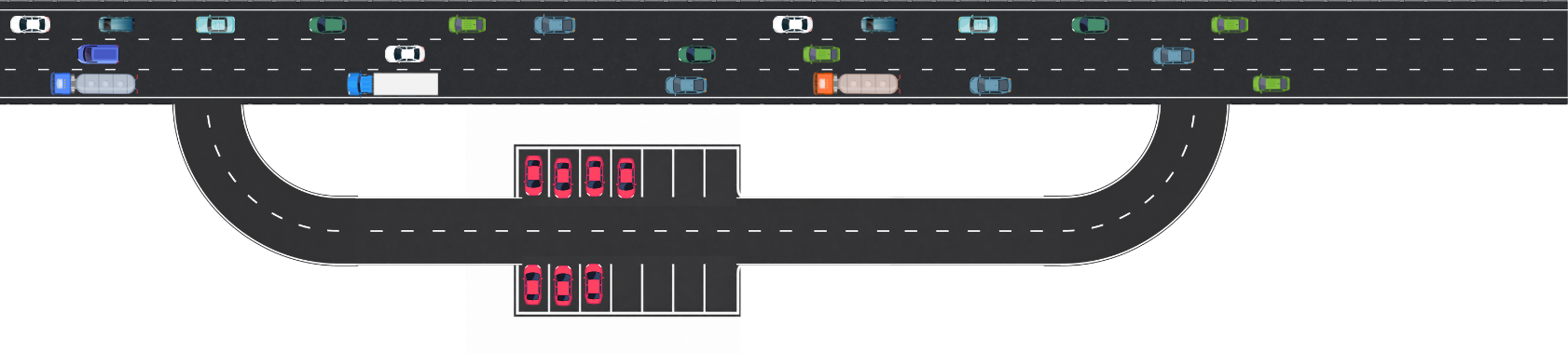
As traffic flows down the motorway, a Highway Officer could spot the red cars and flag them off to your service station. The red cars get parked in a large, dedicated car park. Later, often overnight, you inspect them in one focussed session. Once they’re all inspected and processed, they’re released at the same time back onto the motorway.
This is batch or bucket processing. The advantage is the rest of the traffic isn’t affected, and the processor does less work because it only looks at red cars, instead of every vehicle on the road.
Unfortunately, there’s a delay in processing. You need another service to do the flagging (the Highway Officer) and you need a big storage area (the car park) and critically, while the batch is being processed, the red cars are sitting still. It works well when you need to see where everything is, but the delay to the red cars is a challenge in a real-time world.
Rolling Inspection (Orchestration)
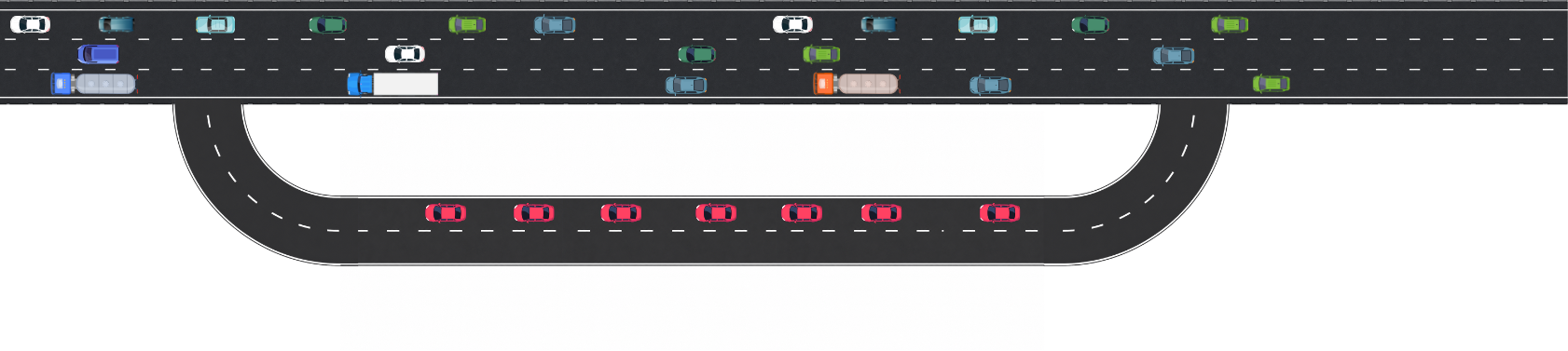
A third option is to keep the red cars moving. This time a Highway Officer could spot red cars and flag them off the motorway. The red cars travel slowly down the service station exit without stopping. As they drive by, they’re inspected automatically. The moment the inspection is complete, they rejoin the motorway and continue their journey.
This is an example of orchestration, where the main pipeline keeps moving while specialist processes are triggered only when they are needed.
That makes it faster, more flexible and less disruptive, especially when only certain data needs checking, transforming or routing. Instead of stopping everything like ETL, or parking work up for later like batch processing, orchestration allows specific tasks to be handled in parallel and returned to the flow once complete.
The challenge of this approach is ensuring close cooperation between different components i.e. the Highway Officer, the inspection service, the rejoin process.
The Evolution of FME
These three processes mirror the journey of FME. It started as a traditional ETL platform where data pipelines were batch-oriented and predictable.
Then the world changed with real-time data becoming more important, data pipelines getting faster and everything growing more complex. Over the years, FME has evolved dramatically with this shift in the data landscape. It still supports batch and traditional ETL but FME’s orchestration capabilities have become remarkable. Through data virtualisation, Event Grid integration, and other native orchestration tools, FME has become built for the drive-by world.
When You’re Asked to Count All the Red Cars
You have choices now. You can stop the motorway when that makes sense. You can park the cars when batch processing is the right approach or you can keep everything moving with orchestration.
Most organisations need a combination of all three. FME gives you that flexibility, and it works alongside the data infrastructure you have already invested in, whether that is Azure Data Factory, AWS Glue, Google Dataflow or something else entirely.
You do not have to tear out your existing motorway. You do not have to choose between stopping traffic and parking cars. You can use the right approach for the right situation, and when the job calls for it, you can keep the data flowing.
Want to know more? Download our PDF…
Insightful, shareable, available here.
Visit The Miso Arms
Read more about Cloud...
Cloud Tool Spend Is Spiralling. Here’s How to Take Back Control.
Cloud was supposed to make cost simpler, but as we’ve developed hybrid infrastructures and incorporated more tools it’s become exponentially more difficult to manage.
Read MoreYour cloud estate is evolving. Your data tools need to evolve with it.
Your environment didn’t appear overnight. It evolved with every platform decision, every architecture review, and every workload that moved to the cloud. The problem is that most data tools were built for a specific moment in that journey.
Read More5 qualities that your cloud data tools need
If our environments are in flux, the tools underneath them need to cope with that and not become another constraint. So rather than choosing a tool for one environment, we should be looking for the qualities that let it keep working across many.
Read MoreData Sovereignty Has an Ownership Problem
We’ve focused heavily on control, and in doing so, we’re starting to lose sight of the ownership of our data.
Read MoreThe carpenter rarely buys a new hammer, and neither should your IT Team
Mastery comes from using the same tools often, not constantly switching between new ones. The pressure is on IT teams to do the opposite.
Read MoreWhat is Cloud 1.0, 2.0, and 3.0, and why does it need LESS technology?
Cloud has fundamentally changed how organisations store and process data. What we’re calling “cloud” isn’t just about location, it’s actually a set of operating models that shape cost structures, skill requirements, and how easily a business can adapt over time.
Read MoreThe Myth of the One-Way Cloud
If you still think of FME as a desktop tool, you’re already behind. The cloud-first features make deployment, scaling, and cost management easier, smarter, and more efficient.
Read More